
行銷與客服團隊必須面對的內容革命:打造靠譜賴管家智能助理的內容指南
2026-01-16
一、你的精美文案,正在毒害你的 AI
去年底的某個下午,賴管家客戶的客服主管發現了一個令人頭痛的問題:他們剛上線的 AI 客服機器人告訴顧客,某款已經停售半年的手機殼「現正優惠中」。更糟的是,當顧客追問詳情時,機器人還煞有介事地報出了一個根本不存在的折扣代碼。
這不是 AI 故障,也不是工程師寫錯程式。真正的兇手藏在公司雲端硬碟深處 — — 一份兩年前的促銷企劃 PDF,從來沒有人想過要刪除它。AI 就像一個過目不忘但缺乏判斷力的實習生,把所有看到的資料都當成了真理。
這個場景,正在全球數以萬計導入檢索增強生成(Retrieval-Augmented Generation, RAG)技術的企業中重複上演。我們花了大把預算買最先進的 AI 模型,聘請頂尖工程師搭建系統,卻忽略了最根本的問題:餵給 AI 的內容,根本不是為機器設計的。
過去十年,數位行銷人員被訓練成說故事的高手。我們學會用情感打動人心,用視覺吸引眼球,用隱喻創造想像空間。客服團隊則習慣在 Slack 頻道裡快速交換解決方案,讓資深同仁的「隱性知識」(Tribal Knowledge) 代代相傳。這些做法在人類世界運作良好,但在 AI 眼中,它們就像是用注音寫成的程式碼 — — 看得懂每個字,卻完全無法執行。
現在,遊戲規則變了。當企業開始讓 AI 代表品牌發言、回答顧客問題、甚至做出商業決策時,內容創作者必須理解一個殘酷的事實:你寫的每一個字、設計的每一份文件,都在訓練 AI 如何思考。 如果你的文案模稜兩可,AI 就會給出模稜兩可的答案。如果你的政策文件前後矛盾,AI 就會自信滿滿地撒謊。
這不是技術問題,而是內容問題。而內容,從來都是行銷和客服團隊的地盤。
二、內容即程式碼:一場認知革命
「內容即程式碼」(Content as Code) 這個概念,聽起來像是工程師的術語遊戲,但它揭示了一個深刻的範式轉移。
過去,我們把內容視為「資產」 — — 要美觀、要吸引人、要能講故事。一篇好的產品文案,可能用了華麗的修辭:「這款咖啡機是廚房裡的藝術品,讓每個早晨都成為儀式」。一份精心設計的產品手冊,可能把規格表放在最後,用大量篇幅描述使用情境和生活方式。
但在 RAG 系統眼中,這些「優質內容」可能是災難。當消費者問「這款咖啡機有幾個鍋爐?」時,AI 必須在文件中搜尋答案。如果你的文案寫著「它採用雙鍋爐系統,確保溫度穩定」,AI 可能會抓到這句話。但如果下一段用「該設備」、「這個機器」來指稱,一旦文件被分割成小塊(技術上稱為「分塊」,Chunking),AI 就會迷失 — — 它不知道「該設備」指的是哪一款產品。
這就是 RAG 的運作邏輯。系統會把你的文件切成 300 到 500 字的小塊,當用戶提問時,AI 會搜尋最相關的幾個小塊,然後根據這些片段生成答案。問題來了:如果每個小塊無法獨立存在、無法自我解釋,整個系統就會崩潰。
讓我們看一個實際案例。某家手機門店的產品頁面這樣寫:
Galaxy Pro 旗艦機
它配備業界最大的感光元件。憑藉先進的夜拍演算法,該裝置在低光環境下表現卓越。用戶讚譽它的拍照能力。
看起來沒問題?但如果 RAG 系統把文件分成兩塊:
第一塊:「Galaxy Pro 旗艦機。它配備業界最大的感光元件。」
第二塊:「憑藉先進的夜拍演算法,該裝置在低光環境下表現卓越。用戶讚譽它的拍照能力。」
當消費者問「哪款手機夜拍好?」時,AI 可能只檢索到第二塊。但第二塊裡沒有產品名稱,只有「該裝置」。AI 無法回答是哪款手機。
解決方案是什麼?名詞最大化 (Noun-maxing)。把文案改寫成:
Galaxy Pro 旗艦機
Galaxy Pro 配備業界最大的感光元件。憑藉先進的夜拍演算法,Galaxy Pro 在低光環境下表現卓越。用戶讚譽 Galaxy Pro 的拍照能力。
這在文學上顯得重複累贅,但在 AI 世界裡,這叫做「上下文獨立性」(Contextual Independence) — — 每一段都能獨立存在,不依賴前後文。這是 RAG 時代內容寫作的黃金法則。
更深層的變化在於:內容創作者必須開始像程式設計師一樣思考。 你不是在寫給人看的故事,而是在寫給機器執行的指令。每個句子都是一行程式碼,每個文件都是一個函式庫。如果你的「程式碼」有 bug(模稜兩可、前後矛盾、缺少關鍵資訊),AI 就會產生「幻覺」(Hallucination) — — 用聽起來合理但實際錯誤的內容欺騙用戶。
這種思維轉變,對行銷人員來說是一場革命。我們過去追求的創意、驚喜、情感共鳴,現在必須與結構、精確、語義清晰並存。這不是說要放棄創意,而是要學會「雙軌創作」:一套內容給人類看,另一套給 AI 讀。
三、行銷內容的三大陷阱
陷阱一:華麗的隱喻,致命的誤導
台灣某家新創科技公司曾在產品頁面上寫:「這款智慧手錶是你手腕上的健身教練」。聽起來很棒,對吧?但當他們導入 AI 客服後,災難發生了。有顧客問:「手錶有語音指導功能嗎?」AI 回答:「是的,作為手腕上的健身教練,本產品提供即時語音指導。」
問題是,這款手錶根本沒有語音功能。AI 把隱喻當成了事實。在它的理解中,「健身教練」會說話,所以「手腕上的健身教練」也應該會說話。
這揭示了一個殘酷的真相:AI 沒有常識,也不懂隱喻。 它是一個字面主義者,會把你的修辭手法當成產品規格。當你說「這款相機是攝影師的第三隻眼」,AI 可能會誤判它有某種特殊的視覺功能。當你說「像單眼相機一樣強大」,AI 可能會錯誤地回答用戶這是一款可換鏡頭的相機。
解決方案不是完全放棄創意文案,而是採用「影子資產」(Shadow Assets) 策略。你的對外網站可以保持華麗的文案和精美的設計,但要為 RAG 系統另外準備一份「事實清單」 — — 一個純文字文件,剔除所有修辭,只留下「主語-動詞-受詞」的硬梆梆陳述。
公開版本:「在工程卓越的交響樂中滑行」
RAG 版本:「Model S 風阻係數 0.208,懸掛系統採用主動空氣阻尼技術」
這個 RAG 版本可能永遠不會被顧客直接看到,但它是 AI 的「教科書」。當 AI 需要回答具體問題時,它會從這個事實清單中提取答案,而不是試圖解讀你的詩意文案。
陷阱二:格式即訊息,排版即語義
某家電商公司有一份精美的產品型錄 PDF。設計師精心安排了雙欄版面,左邊是產品圖片,右邊是規格說明。但當他們把這份 PDF 餵給 RAG 系統時,AI 讀到的順序是這樣的:
「Galaxy Pro(左欄第一行)256GB(右欄第一行)NT$25,000(左欄第二行)6.5 吋螢幕(右欄第二行)」
結果?當顧客問「Galaxy Pro 多少錢?」時,AI 可能回答「6.5 吋」,因為在它讀取的順序中,這兩個資訊緊鄰。
PDF 是為印刷設計的格式,不是為機器閱讀設計的。它把文字固定在視覺空間中,而 AI 只能按照某種線性順序閱讀。雙欄版面、文字環繞圖片、浮水印、表格合併儲存格 — — 這些在人類眼中一目了然的設計,在 AI 眼中都是噩夢。
行銷團隊必須理解:格式本身就承載著意義。 當你用 H1 標題寫「智慧型手機」,用 H2 寫「Galaxy Pro」,用 H3 寫「儲存容量」,你不只是在美化版面,你是在告訴 AI 這個資訊的層級結構。AI 會知道「256GB」屬於「Galaxy Pro」,而「Galaxy Pro」屬於「智慧型手機」。
最佳實踐是改用 Markdown 格式。這是一種簡單的純文字格式,用符號表示結構:
markdown
# 智慧型手機
## Galaxy Pro
### 儲存容量Galaxy Pro 提供 256GB 儲存空間
## Galaxy Lite
### 儲存容量Galaxy Lite 提供 128GB 儲存空間
這種格式不僅人類容易讀寫,AI 更是經過大量訓練,完全理解其結構。更重要的是,當你維護這種格式的「主版本」內容時,要輸出成 PDF 給客戶看,或轉成網頁,都很容易。但反過來,從 PDF 重建結構,卻困難重重。
陷阱三:法律免責聲明的隱形炸彈
某家金融服務公司的網站,在產品介紹頁面大肆宣傳「低利率方案」,但在頁面最底部用小字寫著「利率需經信用評估核准」。這在人類閱讀時不成問題 — — 我們會翻到最下面看註腳。但 RAG 系統會把長網頁切成很多小塊。關於低利率的段落可能被檢索到,但底部的免責聲明卻被留在了另一個塊裡。
結果就是 AI 可能這樣回答顧客:「我們提供業界最低的 2.5% 利率」 — — 完全沒有提到需要信用審核。這不只是服務品質問題,可能還涉及法律合規風險。
在受監管的產業 — — 金融、醫療、保險 — — 這種風險尤其致命。解決方案是「硬編碼」(Hard-Code) 免責聲明。不要把它們放在頁尾或附錄,而是嵌入到相關內容塊的正文中:
風險版本:
「我們提供低至 2.5% 的優惠利率」(第 2 頁正文)
「*利率需經信用評估核准」(第 10 頁腳註)
安全版本:
安全版本 :
「我們提供低至 2.5% 的優惠利率(需經信用評估核准,實際利率依個人信用狀況而定)」
這樣,無論 AI 檢索到哪個片段,免責聲明永遠跟著利益承諾走。你要犧牲一些閱讀流暢度,但換來的是合規安全和客戶信任。
四、客服知識庫的轉型之路
如果說行銷內容是 RAG 的「輸入端」,那客服知識庫就是「核心資料庫」。這裡儲存著企業最寶貴的智慧:真實客戶遇到的問題,以及經過驗證的解決方案。但現實是,大多數企業的客服知識處於混亂狀態。
從聊天記錄到黃金問答
很多公司想要把歷年累積的客服聊天記錄直接倒進 RAG 系統,認為「這些都是真實對話,AI 應該能學到很多」。這是個危險的想法。
客服對話記錄充滿了噪音:
客戶: 你好
客服: 您好,請問有什麼可以幫您?
客戶: 我想問一下那個東西
客服: 請問您指的是哪個產品呢?
客戶: 就上次買的那個啊
客服: 讓我查一下您的訂單記錄…
客戶: 好的謝謝
客服: 找到了,您是指 X 型號嗎?
客戶: 對對對
這段對話中有用的資訊可能只有最後一輪,但前面佔了 80% 的篇幅。更糟的是,對話中充滿了「那個」、「這個」、「它」等代詞,一旦脫離上下文就失去意義。還有個人資料、訂單編號等敏感資訊,直接放入 RAG 系統會違反 GDPR 或台灣個資法。
正確的做法是「挖掘與提煉」(Mine and Refine):
- 提取主題: 用 AI 或人工分析,找出最常見的 500 個客服主題
- 提煉問答: 針對每個主題,創造一組「黃金問答」 — — 用客戶的語言提問,用標準化的語言回答
- 匿名化: 確保所有個資都被移除
- 結構化: 用一致的模板格式化每個問答
例如,從 50 則關於退貨的對話中,你可以提煉出:
問題: 如果商品已經拆封,還可以退貨嗎?
答案: 若商品已拆封但在鑑賞期內(收到商品後 7 天),且商品本身有瑕疵,可以辦理退貨。若非瑕疵品,拆封後恕無法退貨。請聯繫客服(0800-XXX-XXX)確認您的狀況。
這個答案清楚、完整、包含必要資訊和聯絡方式,AI 可以直接引用。這比 50 則雜亂對話有用一百倍。
從敘事手冊到決策樹
客服標準作業程序 (SOP) 通常寫成長篇敘事:
「當客戶要求退款時,首先確認是否在 30 天鑑賞期內。如果是,且商品未拆封,可立即核准。但若已拆封,需要主管核准,除非商品有瑕疵,這種情況可直接退款,不受 30 天限制。另外要注意,客製化商品不適用退款政策…」
這種寫法對人類客服來說可以運作 — — 我們會在腦中建構邏輯樹,記住各種例外狀況。但對 AI 來說,這是一團混亂的邏輯毛線球。
轉型為「決策樹」格式:
markdown
# 退款政策流程
## 情境 A: 一般商品 + 鑑賞期內(30天內)
### 商品未拆封→ 行動: 立即核准退款
### 商品已拆封→ 行動: 需主管核准→ 例外: 若商品有瑕疵,無需主管核准,直接退款
## 情境 B: 超過鑑賞期→ 行動: 不予退款→ 例外: 若商品有瑕疵,仍可辦理退款
## 情境 C: 客製化商品→ 行動: 不適用退款政策(不論時間或狀況)
這種結構讓 AI 可以精確匹配客戶的情境,找到對應的規則。當客戶問「我買的客製化商品可以退嗎?」,AI 直接跳到情境 C,給出明確答案,而不會被情境 A 和 B 的條件混淆。
知識中心服務 (KCS) 的實踐
最徹底的轉型來自「知識中心服務」(Knowledge-Centered Service, KCS) 方法論。核心概念是:客服人員不只是「解決問題」,更是「創造知識」。
每次客服解決一個新問題或不常見的問題時,他們應該:
- 捕獲: 記錄客戶的原始問法(不要改寫成術語)
- 結構化: 用標準模板寫成知識文章(問題-環境-解決方案-原因)
- 驗證: 下次遇到相同問題時,先搜尋知識庫,驗證方案是否有效
- 改進: 如果方案失效或不完整,立即更新文章
這創造了一個「學習循環」。每個客服互動都讓知識庫更完整。而這個知識庫,就是 RAG 系統的燃料。
關鍵是:客服人員要用「客戶的語言」寫問題。如果客戶說「我的螢幕是黑的」,知識文章的標題就應該是「螢幕是黑的/無法顯示」,而不是技術性的「顯示驅動程式故障」。因為當其他客戶問 AI 相同問題時,他們會用「螢幕黑掉」這種口語,而不是專業術語。
五、格式戰爭:看不見的資料災難
Excel 表格的陷阱
產品團隊給了你一個 Excel 檔案,裡面有 500 個 SKU 的完整規格。你直接上傳給工程師,以為萬事大吉。但當 AI 開始回答問題時,你發現它經常搞錯產品和價格的配對。
問題出在哪?
Excel 表格被 AI 讀取時,常常會「失憶」。假設你的表格是這樣:

RAG 系統會把表格切成小塊。第一塊可能包含標題行和第一筆資料,第二塊包含第二筆資料…但如果分塊恰好把標題和資料分開,AI 就會看到:
塊 1: 產品型號 | 容量 | 價格 | 顏色
塊 2: Model Y | 128GB | $300 | 白色
區塊 2:Model Y | 128GB | $300 | 白色
當客戶問「Model Y 多少錢?」,AI 檢索到塊 2,但塊 2 裡沒有說明「128GB」是容量、「$300」是價格 — — 因為標題在塊 1。AI 可能會胡亂配對,回答「Model Y 128GB 美元」。
解決方案是「線性化」 — — 把表格轉成句子:
Model X 配備 256GB 容量,售價 $500,提供黑色。
Model Y 配備 128GB 容量,售價 $300,提供白色。
這種格式下,每個句子都是完整的、自我解釋的。即使被單獨檢索,AI 也能正確理解。
合併儲存格的災難
更糟的狀況是合併儲存格。假設你的 Excel 這樣設計:
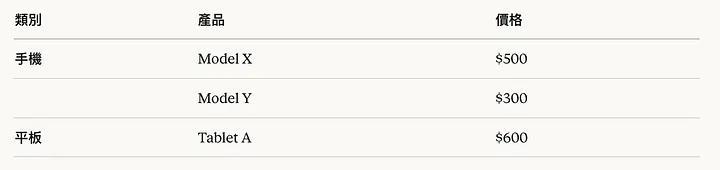
「手機」這個類別儲存格被合併,跨越兩列。在視覺上很清楚,但當 RAG 系統讀取時,它可能只會把「手機」關聯到第一列,導致 Model Y 失去類別標籤。當客戶問「有哪些手機?」,AI 可能只回答 Model X。
規則很簡單:不要合併儲存格。 重複寫「手機」兩次:
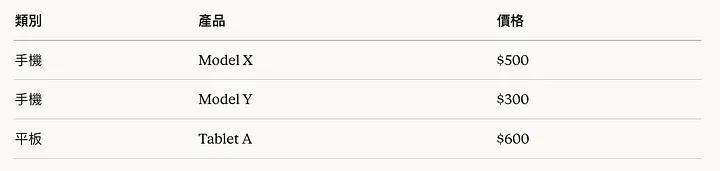
這叫「去規範化」(Denormalization)。在資料庫設計中,規範化是為了避免冗餘。但在 RAG 中,冗餘是你的朋友 — — 它確保每一行都能獨立存在。
圖表與資訊圖的文字化
行銷團隊製作了一張精美的資訊圖,展示「第三季營收成長趨勢」。這張圖可能花了設計師三天時間,包含漸層色彩、3D 立體圖表、品牌視覺元素。但在 RAG 系統眼中,這只是一張圖片 — — 一堆無意義的像素。
目前主流的 RAG 還是基於文字的。雖然多模態 RAG(能「看」圖片)正在發展,但成本高、速度慢、準確度還不如文字檢索。所以當客戶問 AI「第三季營收如何?」,AI 根本「看不到」你那張漂亮圖表裡的資訊。
解決方案是「激進的替代文字」(Aggressive Alt-Text)。不要只寫「營收圖表」,要寫:
「2024 年第三季營收成長條形圖。線上銷售較去年同期成長 20%,達到 900 萬元。實體零售持平於 600 萬元。總營收 1,500 萬元,年成長率 13.3%。」
把圖表裡的每一個數據點都寫成文字。這不只幫助 AI,也符合網頁無障礙標準 (Web Accessibility),對 SEO 也有幫助。你要把每張圖片視為一個需要「翻譯」成文字的視覺故事。
六、誰來掌管 AI 的大腦?
技術問題可以用工程解決,但組織問題才是 RAG 成敗的關鍵。當內容變成程式碼,誰來負責這份「程式碼」的品質?
知識經理的崛起
傳統上,知識管理 (Knowledge Management) 是個模糊的概念,往往沒有人真正「擁有」它。行銷團隊管行銷內容,客服團隊管客服文件,產品團隊管產品規格,IT 管技術文件 — — 每個部門都有自己的檔案櫃,互不干涉。
但在 RAG 時代,這種分散管理是致命的。AI 不關心你的組織架構,它會從所有資料來源中檢索內容。如果行銷的產品手冊說「2 年保固」,客服的 FAQ 說「1 年保固」,產品規格說「依購買方案而定」,AI 就會陷入混亂,隨機選擇一個答案告訴客戶。
企業需要一個新角色:知識經理 (Knowledge Manager)。這個人(或團隊)負責:
- 策展 (Curation): 決定什麼內容該進入 RAG,什麼不該。草稿、內部討論、過時文件都要被排除
- 去重 (Deduplication): 確保同一資訊不會有多個衝突版本
- 標記 (Tagging): 為文件加上「產品類型」、「適用地區」、「發布日期」等元資料,幫助 AI 精準檢索
- 翻譯 (Translation): 在業務團隊和技術團隊之間溝通 — — 把「AI 亂回答」翻譯成「第 3 頁和第 7 頁的政策說明互相矛盾」
這個角色不應該由 IT 部門擔任,因為他們不懂業務細節。也不應該由某個部門兼任,因為會淪為「沒人真正負責」。知識經理應該直接向高層匯報,有權要求各部門配合數據治理規範。
紅隊測試:在災難發生前找到問題
軟體開發有「測試驅動開發」(Test-Driven Development),RAG 也需要「測試驅動內容」。在系統上線前,行銷和客服團隊應該化身為「紅隊」 — — 試圖讓 AI 出錯的測試者。
測試流程:
- 設計邊緣案例: 想出 50 個「刁鑽問題」 — — 那些會讓人類客服頓一下才能回答的問題。例如:「如果我在週年慶優惠期間買的商品,但用振興券付款,退貨時怎麼退款?」
- 驗證答案與來源: 檢查 AI 的回答是否正確,更重要的是,檢查它引用了哪些文件。如果答案對但來源錯(例如引用了已過期的政策),這也是問題。
- 診斷失敗原因:
- 資料缺失: 根本沒有文件涵蓋這個情境 → 寫一份
- 資料衝突: 找到兩份矛盾的文件 → 刪除舊的
- 格式問題: 資料存在但 AI 讀不懂(例如複雜表格) → 重新格式化
4. 建立回歸測試集: 把這 50 個問題存檔。每次更新知識庫後,重新跑一遍,確保沒有「修好 A 卻破壞 B」。
這個過程要定期進行,至少每季一次。因為知識庫是活的 — — 產品會更新、政策會改變、新問題會出現。沒有持續測試,你的 RAG 系統會在不知不覺中腐敗。
單一事實來源的鐵律
最危險的情況是「多版本並存」。某個促銷政策,網站上是 A 版本,雲端硬碟裡的 PDF 是 B 版本,客服系統裡的 FAQ 是 C 版本。人類員工可能知道「以最新版本為準」,但 AI 不知道。它可能隨機選一個,或更糟 — — 把三個版本混在一起,創造一個從未存在過的「D 版本」。
解決方案是「單一事實來源」(Single Source of Truth, SSOT)。對每類資訊,只維護一份主版本:
- 產品規格: 由產品管理系統 (PIM) 管理,其他地方都從這裡匯入
- 服務政策: 由法務部門維護在內部 Wiki,客服手冊和網站都引用這個來源
- 價格資訊: 由財務系統管理,行銷和客服都不能自己編輯
當主版本更新時,所有衍生版本(網站、PDF、RAG 資料庫)應該自動或在 24 小時內同步更新。這需要技術流程支援,但更需要組織紀律 — — 沒有人可以「為了方便」在自己的檔案裡保留一份副本並修改。
七、重新定義內容的價值
當我們談論 RAG 數據準備,表面上是在談技術和流程,但本質上是在重新定義「好內容」。
過去,一篇「好的」產品文案,是由點擊率、停留時間、轉換率來衡量的。一份「好的」客服文件,是由客服人員「好不好用」來評估的。這些指標仍然重要,但不再是全部。
在 AI 時代,內容的價值還包括:
- 可檢索性 (Retrievability): AI 能不能找到它?
- 可理解性 (Comprehensibility): AI 讀懂了嗎?
- 可驗證性 (Verifiability): 答案有沒有明確的來源?
- 時效性 (Freshness): 資訊是最新的嗎?
一篇華麗但模糊的品牌故事文章,可檢索性可能是零。一份設計精美但結構混亂的 PDF 手冊,可理解性可能很低。這些在人類世界裡的「優質資產」,在 AI 世界裡可能是「垃圾」。
反過來,一份樸實無華、結構清晰的 Markdown 文件,用「上下文獨立」原則寫成的產品規格列表,對 AI 來說是「黃金」。它可能永遠不會被顧客直接看到,但它支撐著成千上萬次 AI 與客戶的互動。
這是一場價值的倒置。 內容創作者必須接受:那些在幕後默默支撐 AI 運作的結構化文件,可能比精心製作的宣傳影片更有商業價值。因為它們讓 AI 能夠 7×24 小時、以零邊際成本服務客戶,回答問題,解決問題,甚至完成交易。
更深遠的影響是,行銷和客服團隊的角色正在轉變。過去,我們是「對外溝通的專家」,直接面對客戶。現在,我們還要成為「對內編碼的工程師」,訓練代表我們與客戶互動的 AI。
這不是要消滅創意或情感,而是要建立「雙軌創作」的能力:一條軌道服務人類的心,用故事、情感、視覺打動人心;另一條軌道服務機器的腦,用結構、精確、邏輯餵養 AI。兩條軌道都不可或缺,兩種技能都要掌握。
當你下次打開 Word 文件,準備寫一份產品介紹或客服政策時,問自己:「如果這份文件被切成碎片,每一片是否仍能獨立存在?如果一個沒有常識的機器讀到它,會不會誤解我的意思?」
因為在不遠的未來,那個機器可能就是你公司的第一線服務代表。而你寫的每一個字,都在程式設計它如何代表你的品牌說話。
內容即程式碼,不是隱喻,而是現實。 是時候像對待程式碼一樣,以嚴謹、結構化、可驗證的態度對待我們的內容了。這不是技術部門的工作,這是每一個創造內容的人 — — 行銷、客服、產品 — — 在 AI 時代的新使命。
-------------------------------------
賴管家AI 助理正是為解決這個問題而生。它能夠學習您企業的專屬知識,打造真正懂得您業務的智能客服系統。
輕鬆建立企業知識庫
賴管家提供多種便捷的資料輸入方式,讓您輕鬆建立專屬的企業知識庫
1. 直接輸入模式
- 像聊天一樣輸入產品資訊
- 即時更新業務政策
- 隨手記錄常見問題解答
2. 檔案上傳功能
- 上傳產品型錄 PDF
- 匯入服務手冊文件
- 導入教育訓練資料
3. 網址匯入功能
- 自動擷取官網資訊
- 同步部落格文章
- 整合線上資源
